Generating Descendant Table Using Spark GraphX
Generating Descendant Table Using Spark GraphX
Hierarchical data is very common in business domain modeling. An org chart, for example, shows the reporting hierarchies of employees in an organization. This hierarchical model is important and can be used in enterprise software systems for fine-grain data access control.
In this article, I will demonstrate how we can use Apache Spark's GraphX library to model hierarchical data and implement a graph algorithm using Pregel API to generate a descendant table for use in row-level access control.
Implementing Access Control Using Descendant Table
Generic row-level access control on employee data is a common security requirement. For instance, the CEO of a company should be able to see all employee data, while a middle manager can only see data from her direct and down line reports.
One simple way to achieve this filtering of data dynamically, is to use a descendant table as an access control lookup.
For example, given an org chart:
CEO├── COO├── CTO│ ├── Manager A│ │ └── Supervisor│ │ └── Team Lead│ │ └── Developer│ └── Manager B└── CFO
We can model this hierarchy using a Descendant Table: a table that contains all reporting pairs of employee and his or her entire upper management chain. Below is an example of a descendant table generated from the org chart above.
| Employee | ReportingTo |
|---|---|
| CEO | - |
| COO | CEO |
| CFO | CEO |
| Manager A | CEO |
| Manager A | CTO |
| Manager B | CEO |
| Manager B | CTO |
| Supervisor | CEO |
| Supervisor | CTO |
| Supervisor | Manager A |
| Team Lead | CEO |
| Team Lead | CTO |
| Team Lead | Manager A |
| Team Lead | Supervisor |
| Developer | CEO |
| Developer | CTO |
| Developer | Manager A |
| Developer | Supervisor |
| Developer | Team Lead |
If you want to filter a Fact Table like the one below...
| Employee | Rating |
|---|---|
| Developer | Good |
| Team Lead | Average |
| Supervisor | Excellent |
You can join the Descendant Table with the Fact Table and filter
ReportingTo column with the current active user. A simple SQL query should
do the trick.
select * from descendant dinner join fact f on f.Employee = d.Employeewhere ReportingTo = [User]
Generating the Descendant Table
Normally, employee tables would contain information about their direct line manager only. And the entire reporting structure (ie. their manager's manager) may have to be recursively queried from the same table.
Performing this query on a relational database can be quite inefficient. In this scenario, a graph based algorithm is better suited.
In this article, I am going to use Apache Spark's GraphX library and specifically the Pregel API to generate the descendant table. You can refer to the GraphX guide for more details on how to use this library.
I chose Spark since I intend to use this code on a large dataset and performance is a key factor. I am using a small dataset for demonstration purposes only.
First, let's generate a sample data that may be typical of an employee table.
The data includes some information about the employee and a reference ID to the
employee's supervisor supervisorId. Note that the CEO doesn't have a
supervisor.
type Role = Stringcase class Employee(name: String, role: Role)val employeeRawData = Array((1L, "Steve", "Jobs", "CEO", None),(2L, "Leslie", "Lamport", "CTO", Some(1L)),(3L, "Jason", "Fried", "Manager", Some(1L)),(4L, "Joel", "Spolsky", "Manager", Some(2L)),(5L, "Jeff", "Dean", "Lead", Some(4L)),(6L, "Martin", "Odersky", "Sr.Dev", Some(5L)),(7L, "Linus", "Trovalds", "Dev", Some(6L)),(8L, "Steve", "Wozniak", "Dev", Some(6L)),(9L, "Matei", "Zaharia", "Dev", Some(6L)),(10L, "James", "Faeldon", "Intern", Some(7L)))val employeeDf = sc.parallelize(employeeRawData, 4).toDF("employeeId","firstName","lastName","role","supervisorId")
Next, we generate the graph model using the basic building blocks -- vertices and edges.
val verticesRdd: RDD[(VertexId, Employee)] = employeeDf.select($"employeeId", concat($"firstName", lit(" "), $"lastName"), $"role").rdd.map(emp => (emp.getLong(0), Employee(emp.getString(1), emp.getString(2))))val edgesRdd: RDD[Edge[String]] = employeeDf// Remove vertices without supervisor, in Scala None === Null.filter($"supervisorId".isNotNull)// First column is supervisorID (not employeeId), since direction of edge is top-down.select($"supervisorId", $"employeeId", $"role")// Edge property is the Role.rdd.map(emp => Edge(emp.getLong(0), emp.getLong(1), emp.getString(2)))// Define a default employee in case there are missing employee referenced in Graphval missingEmployee = Employee("John Doe", "Unknown")// Let's build the graph modelval employeeGraph: Graph[Employee, String] = Graph(verticesRdd, edgesRdd, missingEmployee)
Let's create case classes to model the vertex values as well as the messages that will be used for the Pregel API. I recommend, using case classes as oppose to tuples when working in Spark as it improves code readability.
// The structure of the message to be passed to verticescase class EmployeeMessage(currentId: Long, // Tracks the most recent vertex appended to path and used for flagging isCycliclevel: Int, // The number of up-line supervisors (level in reporting heirarchy)head: String, // The top-most supervisorpath: List[String], // The reporting path to the the top-most supervisorisCyclic: Boolean, // Is the reporting structure of the employee cyclicisLeaf: Boolean // Is the employee rank and file (no down-line reporting employee))// The structure of the vertex values of the graphcase class EmployeeValue(name: String, // The employee namecurrentId: Long, // Initial value is the employeeIdlevel: Int, // Initial value is zerohead: String, // Initial value is this employee's namepath: List[String], // Initial value contains this employee's name onlyisCyclic: Boolean, // Initial value is falseisLeaf: Boolean // Initial value is true)
Let's initialize the vertex values.
// Initialize the employee verticesval employeeValueGraph: Graph[EmployeeValue, String] = employeeGraph.mapVertices { (id, v) =>EmployeeValue(name = v.name,currentId = id,level = 0,head = v.name,path = List(v.name),isCyclic = false,isLeaf = false)}
Now, let's encode the graph algorithm using the Pregel API superstep functions
making sure to handle cyclic structures (ex. A reports to B, B reports to C, and
C reports to A). In case of a cyclic structures, we will use an isCyclic flag
to indicate all employees in the cycle.
/*** Step 1: Mutate the value of the vertices, based on the message received*/def vprog(vertexId: VertexId,value: EmployeeValue,message: EmployeeMessage): EmployeeValue = {if (message.level == 0) { //superstep 0 - initializevalue.copy(level = value.level + 1)} else if (message.isCyclic) { // set isCyclicvalue.copy(isCyclic = true)} else if (!message.isLeaf) { // set isleafvalue.copy(isLeaf = false)} else { // set new valuesvalue.copy(currentId = message.currentId,level = value.level + 1,head = message.head,path = value.name :: message.path)}}/*** Step 2: For all triplets that received a message -- meaning, any of the two vertices* received a message from the previous step -- then compose and send a message.*/def sendMsg(triplet: EdgeTriplet[EmployeeValue, String]): Iterator[(VertexId, EmployeeMessage)] = {val src = triplet.srcAttrval dst = triplet.dstAttr// Handle cyclic reporting structureif (src.currentId == triplet.dstId || src.currentId == dst.currentId) {if (!src.isCyclic) { // Set isCyclicIterator((triplet.dstId, EmployeeMessage(currentId = src.currentId,level = src.level,head = src.head,path = src.path,isCyclic = true,isLeaf = src.isLeaf)))} else { // Already marked as isCyclic (possibly, from previous superstep) so ignoreIterator.empty}} else { // Regular reporting structureif (src.isLeaf) { // Initially every vertex is leaf. Since this is a source then it should NOT be a leaf, updateIterator((triplet.srcId, EmployeeMessage(currentId = src.currentId,level = src.level,head = src.head,path = src.path,isCyclic = false,isLeaf = false // This is the only important value here)))} else { // Set new values by propagating source values to destination//Iterator.emptyIterator((triplet.dstId, EmployeeMessage(currentId = src.currentId,level = src.level,head = src.head,path = src.path,isCyclic = false, // Set to false so that cyclic updating is ignored in vprogisLeaf = true // Set to true so that leaf updating is ignored in vprog)))}}}/*** Step 3: Merge all inbound messages to a vertex. No special merging needed for this use case.*/def mergeMsg(msg1: EmployeeMessage, msg2: EmployeeMessage): EmployeeMessage = msg2
Let's run the graph algorithm.
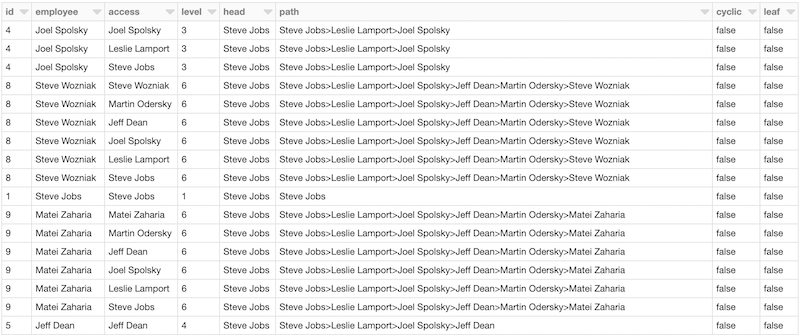
val initialMsg = EmployeeMessage(currentId = 0L,level = 0,head = "",path = Nil,isCyclic = false,isLeaf = true)val results = employeeValueGraph.pregel(initialMsg,Int.MaxValue,EdgeDirection.Out)(vprog,sendMsg,mergeMsg)val resultDf = results.vertices.map { case (id, v) => (id, v.name, v.level, v.head, v.path.reverse.mkString(">"), v.isCyclic, v.isLeaf) }.toDF("id", "employee", "level", "head", "path", "cyclic", "leaf")display(resultDf)
The vertex values' path column contains all the employees upper management
chain.

Finally, we can generate the descendant table by doing a simple flatMap on the
path. You can now use the access column to join with your fact table,
similarly to how ReportingTo works in our initial example.
val acl = results.vertices.flatMap { case (id, v) =>v.path.map(p => ((id, v.name, p, v.level, v.head, v.path.reverse.mkString(">"), v.isCyclic, v.isLeaf)))}.toDF("id", "employee", "access", "level", "head", "path", "cyclic", "leaf")display(acl)
You can find [the entire code on Github. I've tested the code on Scala 2.11, Spark 5.5. The code is a Databricks Scala notebook that you can easily import and run on your own Apache Spark cluster.